




Introduction
AWS AppSync is a fully managed service that allows developers to create and manage scalable APIs for their applications. It provides both real-time data and offline-access capabilities, making it easy to build and deploy applications that require high-performance, responsive data access.
With AWS AppSync, developers can easily connect their applications to a variety of data sources, including relational databases, NoSQL data stores like DynamoDB, existing REST APIs , and use GraphQL to retrieve and manipulate data. This makes it possible for developers to quickly and easily build complex, data-driven applications that can deliver rich, engaging user experiences.
To resolve data from these datasources, AppSync uses what's known as a pipeline resolver to sequence the flow of data.
In this post, we'll learn about pipeline resolvers, why they're beneficial, and see examples of the various types that datasource integrations that AppSync supports.
This post is aimed at folks that have experience with GraphQL and or AWS AppSync.
If you are completely new, feel free to check out this video that will walk you through getting started!
Understanding pipeline resolvers
A pipeline resolver is a way to organize and manage the flow of data between your application and data sources. It allows you to specify a sequence of operations that should be performed on data as it is retrieved from one or multiple data sources. As the data moves through the pipeline, operations can take place. These operations can include filtering, sorting, and transforming the data, as well as combining data from multiple sources. This enables you to create complex, data-driven applications that can deliver rich, engaging user experiences.
📘 It's an important concept to note that a pipeline represents a sequence. There is no branching in the pipeline, and the steps are performed synchronously.
At a high level, a pipeline consists of the following:
A pipeline before step
A sequence of functions to perform
A pipeline after step
What makes AppSync's GraphQL model so powerful is when we introduce the idea of a datasource--that is when a user makes a request for data, where that data is coming from. The pipeline fulfills the request for data, whereas the datasource is what houses it.
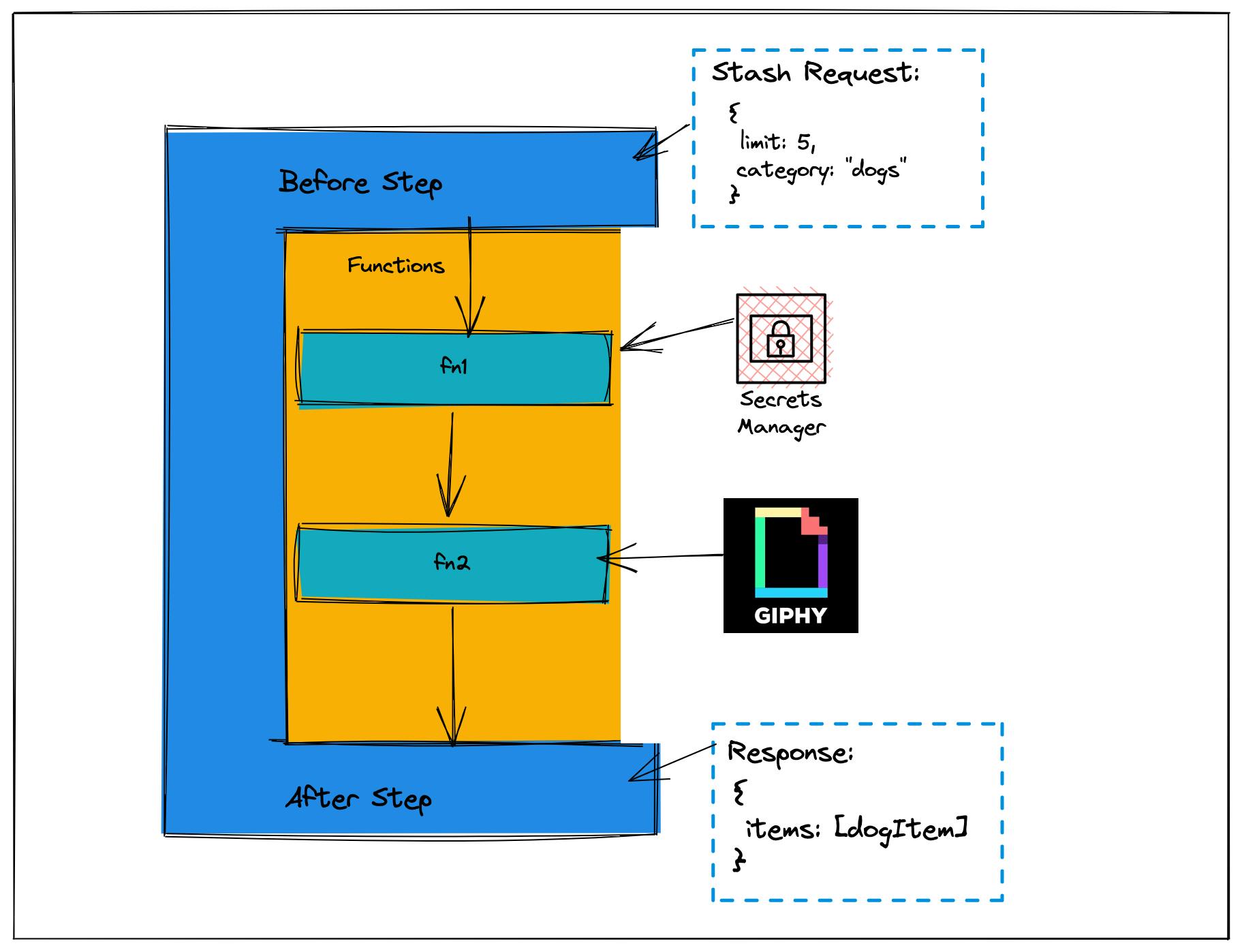
The best part about this model is that a pipeline can be connected to a datasource, as well as each individual function within the pipeline.
To help cement this idea, let's look at an example.
A practical example of a pipeline resolver
All requests require a secret value
One of the most common ways I see folks using pipeline resolvers is when they need to get a secret value and then perform their actual query or mutation.
Imagine we have a pet API that will provide details about a pet. The API requires an API key that we store in a safe place (not on the client). All we have to do on the frontend is tell the API how many items we'd like back, and what category of pet we'd like information on.
If we were to write this out in a Lambda function, that function would serve four roles:
Taking in the request from the user
Grabbing a secret value
Accessing the database by combining the request with the secret value
Returning that response to the user
Further, we now have to manage this code, the Lambda, and factor in cold starts.
With a pipeline resolver, the code we write is managed by AppSync. There are no servers and it lives in its own execution environment. This means one less service to manage, and not having to deal with cold starts.
In the following example, our "database" will be the Giphy API.
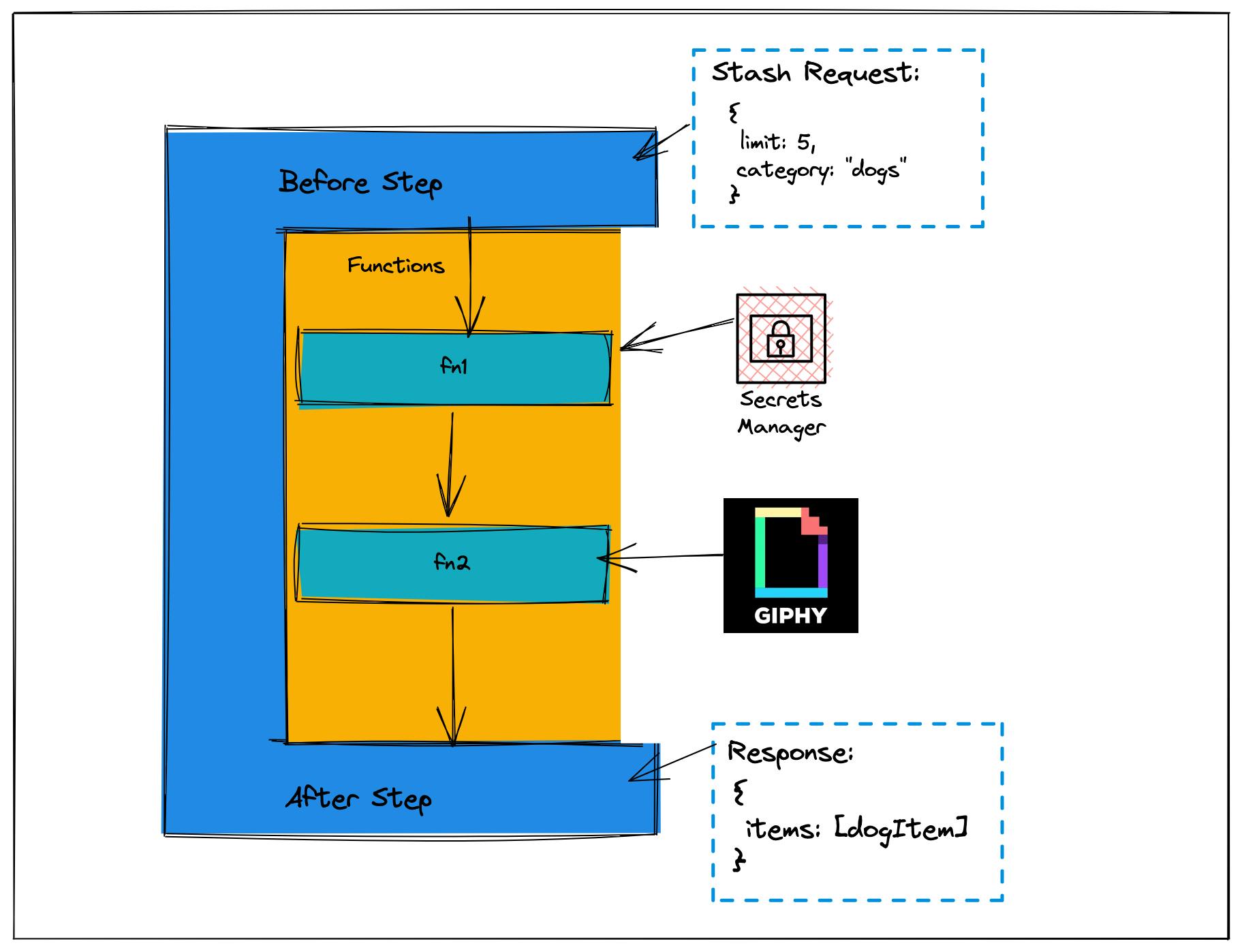
In a pipeline workflow, our before step says "Great, this is a query about five dog items. Let me tuck that away later." This is known as the stash and is how values can be stored for later use.
// The `before` step
export function request(context) {
context.stash.put('category', context.args.category)
context.stash.put('limit', context.args.limit)
// whatever gets returned, gets passed on to the next step
return {}
}
Next up, there is a function that uses an HTTP datasource to grab the value from Secrets Manager. Since it's an HTTP request, we can use an endpoint for the service.
// Reusable function to get a secret value for fetching pet info
export function request(context) {
return {
method: "POST",
version: "2018-05-29",
resourcePath: "/",
params: {
headers: {
"content-type": "application/x-amz-json-1.1",
"x-amz-target": "secretsmanager.GetSecretValue"
},
body: {
SecretId: "MyAPIKeyName" // the name (not value) of the Key
}
}
}
}
// Parse the response and hand it to fn2
export function response (context) {
//context.result.body = `{SecretString: {SecretId: "my-api-key"}`
const result = JSON.parse(context.result.body).SecretString
return result
}
What's great about the code above is that it looks like a serverless function, feels like a serverless function, and tastes like a serverless function, but it's not!
We get to write our functions like this and AppSync will handle translating it into what it understands 🤯
Now that we have our secret, we can make the request to our database. AppSync has first-class support for DynamoDB and Aurora Serverless v2. If we were using MongoDB, we could use their Data API to make another HTTP request like above, and for fully custom solutions, you can also use a Lambda function (in AppSync, a Lambda function is considered a datasource).
Above, we showed how to connect to an AWS service API, this is how to connect to an external API:
export function request(ctx) {
// access the result from the previous function
const secret = ctx.prev.result.SecretId
// access stashed values from the `before` step
const category = ctx.stash.category
const limit = ctx.stash.limit
return {
method: "GET",
version: "2018-05-29",
resourcePath: "/v1/gifs/search",
params: {
query: {
api_key: secret,
q: category,
limit
}
}
}
}
// Manipulate the data however makes sense for my application
// Here, I'm storing an array of Gif URLs
export function response(ctx) {
const gifDataJSON.parse(ctx.result.body).data
const urls = []
for(item of gifData) {
urls.push({fixedWidthURL: item.images.fixed_width.url})
}
// Send this data to the next step, the `after` step.
return JSON.stringify(urls)
}
After a while, you'll notice that when it comes to data in a pipeline, we're just sending objects of data on to the next step. If we want to access data from the previous function, we grab it from the .prev.result property. And if we want to access data from the stash, we use the .stash property.
You may have also noticed that each file consists of a request and a response. In plain speak, this is a mapping of "What do you want me to do" and "Once done, where do you want me to send the response".
The last part of our pipeline is our after step and is in charge of making sure the data we return is compliant with the schema that we presumably created.
Imagine the following schema:
type Query {
getGifs(limit: String, category: String!): [Gif]
}
type Gif {
fixedWidthURL: String!
}
Then we can add a response function to our pipeline resolver above to send back data to the client.
//.... function request code
export function response(ctx) {
return JSON.stringify({items: ctx.prev.result})
}
// The client response:
// data.getGifs.items[0].fixedWidthURL
Conclusion
In this post, we discussed the benefits of using an AWS AppSync pipeline resolver. In addition, we saw how to call both an internal and external service using an HTTP integration.
By using AWS AppSync as opposed to a traditional GraphQL implementation, you no longer have to worry about setting up and managing a server. It's all handled for you. In addition, but leveraging an AppSync pipeline resolver, you get code that is both reusable and composable but without any of the tradeoffs that come from using a serverless function.
For more details on AWS AppSync and how to get started, visit the docs. If wanting to set up AppSync in your own application using the AWS CDK, I have a video that showcases how to do just that!