Fullstack Solutions: AWS Amplify Gen 2 vs AWS CDK

I'm sitting in a Seattle pub writing this post and I'm having a hard time conentrating because my Airpods died. It's my fault for not charging them, but I wish I had wired headphones that I could plug in. They would just work™️. I wouldn't have to worry about one earbud losing power, and the initial setup just involves taking them out of the box and plugging them in.

Yet, there's something to love about the flexibility of putting in just one earbud, or exercising without getting tangled in wire, or even the different customizations I can make with pressing, long-pressing, sliding etc.
Maximum ease-of-use vs maximum flexibility.
In case it's not apparent, that's how I felt when comparing AWS Amplify Gen 2 vs my custom AWS solution with the AWS CDK when it came to building fullstack apps.
In this post, I'll discuss some of the similarities between these solutions, their differences, and when I would use one over the other.
🗒️ While this post is intended for fullstack developers, It slants towards those with knowledge of the AWS CDK. If coming from the other end and are more of a frontend developer, I encourage you to read my last post.
AWS CDK for Power and Flexibility
When your next great idea strikes for a fullstack application, there are plenty of times you'll want to reach for the AWS CDK directly. This wrapper around AWS Cloudformation gives developers the freedom to write their backend in TypeScript, Python, Java, and other languages. This can be a huge benefit and unblocker in itself for developers and teams.
Surface Level
Creating a new fullstack application, where the backend is powered by the AWS CDK is powerful and simple:
npm create vite@latest ./ && \
md _backend && \
cd $_ && \
npx aws-cdk init -l typescript \
If you need authentication, an API, a database, file storage, etc, you get to craft those exactly how you want.
Setting up a team-based workflow is also great because you get to specify exactly how you want your workflow to be and what the day-to-day experience will be like.
And when it comes to deployment, you get to have full control on how you'd like it deployed.
These are all great! Personally, from a learning perspective, it also meant I got to understand services at a much more clarified level than using a tool that generated it for me. It helps that I'm never really extending the CDK since I'm working at more or less the same level the whole time. I'm simply building.
Diving Deeper
However, if you re-read the section above and replace each instance of "you get to" with "you have to". Then things start to become much more daunting.
🗒️ It's worth noting that there is a tool called Projen that aims to simplify some of the opinions needed to be made. You can learn more about the Pros and Cons of that package here.
For this reason, I created my own CDK starter repo. It comes with many of the configuration options that I like and simplifies some of the mundane work needed to get my fullstack idea off the ground.
This worked out well because I often build fullstack, monorepo applications. It also comes with basic CRUD operations for my API so I can simply reference them and tweak them accordingly.
At the expense of sounding blasphemous, this was my attempt at creating Amplify Gen 2 before it existed 😅
This is just a personal project though and not something that I guarantee will work for you (I even say so in the readme!).
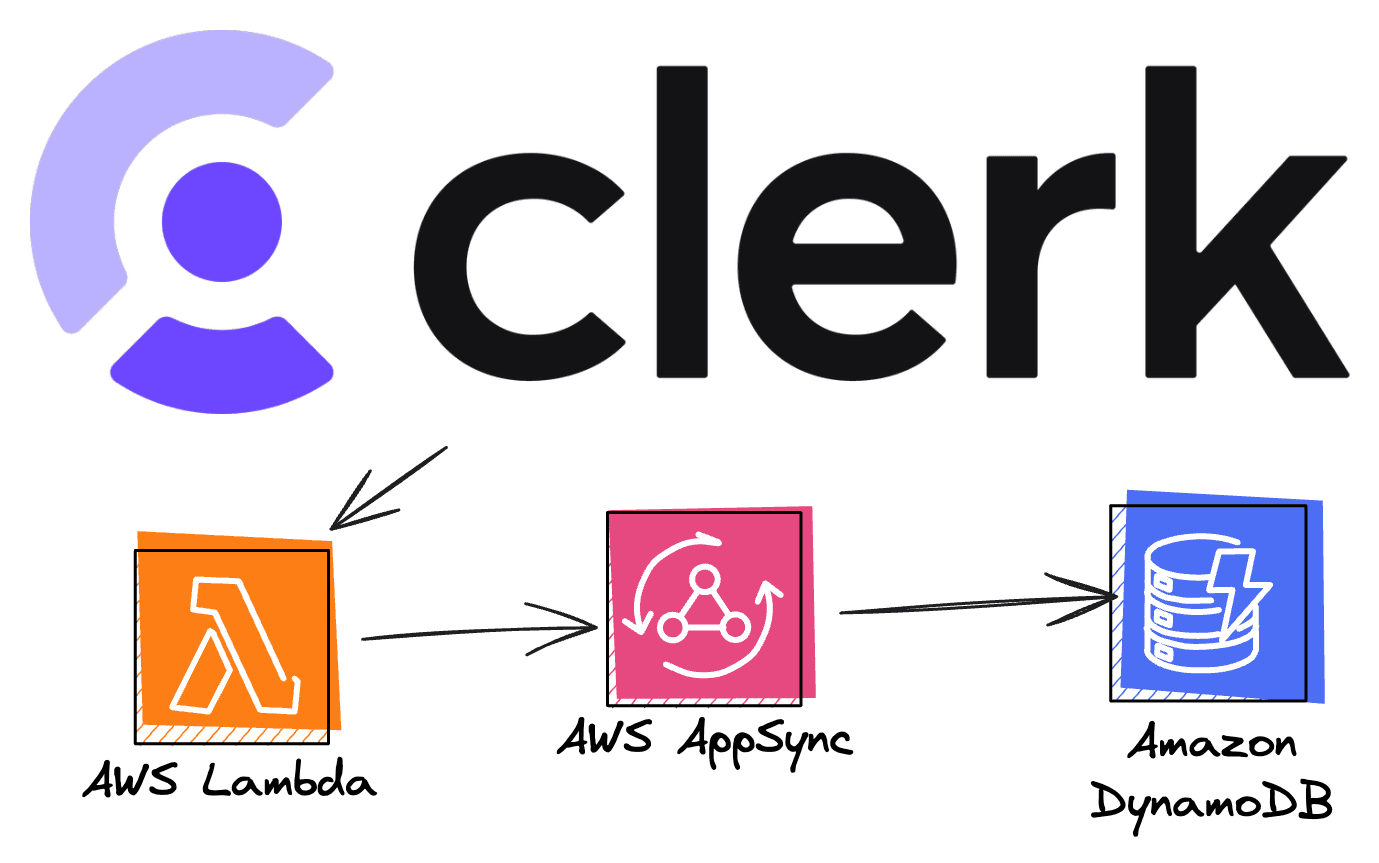
With that said, while the repo I created uses a CDK construct to deploy a frontend to AWS Amplify, maybe that's not what you want. Perhaps you want to keep your frontend and backend separated in different GitHub repos. That's to say, everytime a backend change occurs, a GitHub action will try to build and deploy your changes to AWS.
That's what I built with my GitHub OIDC repo:
Conclusion
I say all of this to highlight the flexibility, and power in setting this up exactly how you want. However, it's time consuming. If you're in a large organization, you've likely already invested the time into this and have something similar to what I created above.
Though, if you are not a large organization the above is a lot of work and probably enough to say "nevermind". At the end of the day, choosing to understand the tools you use will serve you in the long run--greatly impacting the overall Total Cost of Ownership.
AWS Amplify for Speed and Ease of Use
As the AWS CDK wraps Cloudformation so that customers don't have to write extraneous amounts of YAML, AWS Amplify wraps the CDK to provide structure for building fullstack apps*.
I mentioned in a recent post, AWS Amplify in 2024 is not the Amplify you grew up with. Gone are the days of writing a GraphQL schema, or using predefined storage paths like private , protected , and public.
// Setting up a data model in Gen 2 using TypeScript
const schema = a.schema({
Todo: a
.model({
content: a.string(),
})
.authorization((allow) => [allow.guest()]),
})
// Setting up an S3 Bucket with authorization access in Gen 2
const storage = defineStorage({
name: 'myProjectFiles',
access: (allow) => ({
'media/*': [
allow.guest.to(['read'])
]
})
})
In fact, in that last post, I showed how to extend the Amplify service so that custom API operations can be made instead of using the .model helper provided by Amplify.
Surface Level
Creating an application using Amplify is similarly simple to the CDK:
npm create vite@latest\
npm create amplify@latest\
The above is all that is needed to create a fullstack application that is powered by AWS and fully developed in TypeScript.
However, I'd be amiss if I didn't point out that TypeScript being used here isn't a personal preference, it's a requirement as opposed to the AWS CDK. This underscores Amplify being targeted towards fullstack teams and developers (more on this in a bit).
If you are a solo developer, you might have one AWS account. If you're serious dev or a small team, you might have SSO setup. If you're a large org, you probably give every developer their own AWS account. These are just a few ways that day-to-day development is done.
In Amplify Gen 2, none of that matters because every project is developed in its own sandbox:
npx ampx sandbox [--profile=focus-otter]
Gone are the days of stepping on each others workflow. Instead, running the command above will not only do a synth and deploy of your application, but it will also generate the appropriate CDKOutputs and put the backend in watch mode.
When it comes to customizations from the basic CRUD operations that Amplify provides, in Amplify Gen 2 extensibility works differently. Gen 2 resources are file-based instead of CLI-based, so adding custom resources means just writing CDK code.

In the code above, notice how I'm using CDK L2 constructs in my application. Also, take notice of how the type of my myCustomCDKStack item is of type Stack.
Not some Amplify wrapped service. Just a plain 'ol CDK stack!
Diving Deeper
The .model part of the data resource will create an AppSync API, a DynamoDB database, associate the necessary roles/permissions, and generate all of the CRUDL operations + subscriptions, and their types.
That's a lot! But is it too much? I personally don't think so. Doing so by hand is boring and mundane. Every application needs those capabilities, yes. Though if you aren't a fan of those particular services...don't use them 🤷♂️
What I mean is Amplify doesn't bind developers to those services, but does take the opinion that most developers will benefit from this experience. To prove that, compare my CDK starter repo above, with my Amplify Gen2 starter repo here:
My personal Gen 2 starter (not affiliated with the official Amplify Gen 2 starter) just works, comes integrated with it's own sandbox environment instead of me trying to create my own, and if at any point I want to add more features, I simply drop down to using the CDK.
Amplify is doing for the CDK community what Expo did for React Native.
"But Focus Otter, I don't want to have my backend and frontend bundled together."
Great! Amplify Gen 2 no longer has to be tied to one--in fact, it only cares that your backend is written in TypeScript. What you use it for is completely up to you. This unlocks a new category of use cases that is not only documented, but officially supported by the Amplify team.
More on this feature in a future post!
In Amplify Gen 1, I recall having to do things "the Amplify way". There is still some of that, but as someone who has grown fond of developing with the CDK, doing things the Amplify way feels less like a shove in a direction, and more like a guided hand.
Which to use
It would be too easy to write "it depends" and call it a day. So let me offer some practical advice for building fullstack applications on AWS:
Start with Amplify.
My headphone analogy in the beginning falls apart when I consider how deeply integrated Amplify Gen 2 is with the AWS CDK.
Sure, if you don't know JavaScript/TypeScript, then it's not a good fit. Full stop.
If you're Lambda functions aren't in TypeScript, stay tuned.
Remember, that Amplify Hosting integrates with Amplify Gen 2, but they are separate. So if you have your own set of hosting requirements, you can still build with Gen 2.
I can't stress how critical I've been of this new workflow since testing it out internally--and even now. But it's good, really good. Yes, you can spend time coming up with the solutions using the CDK like how I did, but your time is better spent.
Keep in mind, this post is for the masses. That's to say it's not a silver bullet but rather my current opinion on what should be your goto.
That's enough though leadership for me, for the next few weeks I'll be showing a bunch of fun applications that can be built with Amplify Gen 2!
Until then, happy coding 🦦