The Complete Guide to Integrating Clerk with an AWS Backend
Don't get me wrong: I love how simple Amazon Cognito makes it to get email authentication working. It even has direct support for Google and Facebook. But what about authenticating with Notion, GitHub, Slack, etc? That's when I reach for Clerk. Clerk is more than just a auth provider. It's an entire user management platform that makes it really simple to get authentication setup.
However, adding a third-party SaaS when the rest of your application backend is built on AWS can seem tricky. That's why in this post, I'm going to show exactly how to put the two together.
Application Overview
🗒️ All the code relating to this post can be found in the repo above.
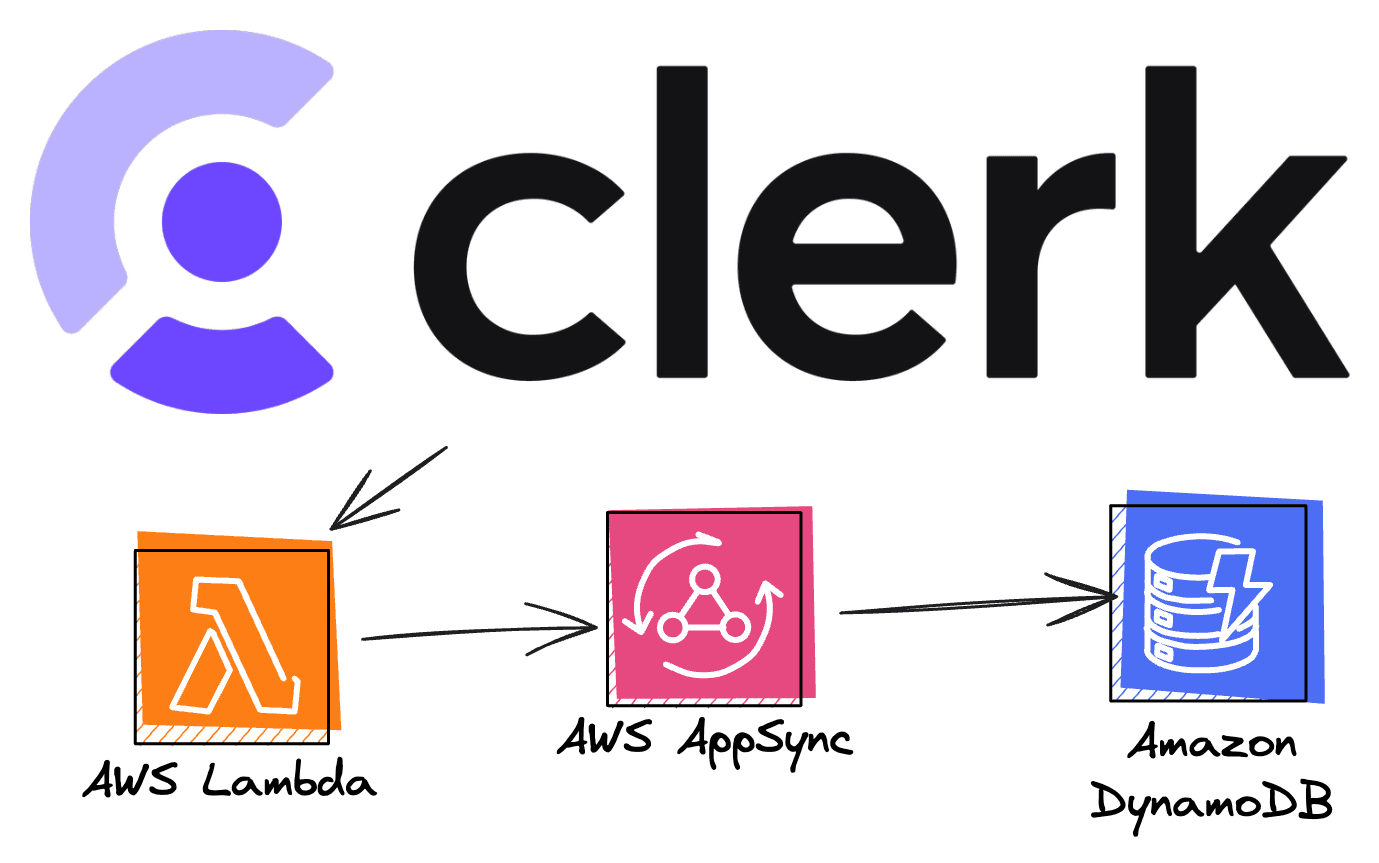
Typically, when I add authorization with AWS, it's with Amazon Cognito. In Amplify Gen 2, this is done for you since when you scaffold your application with npm create amplify, both a data and auth resource are created. However, the underlying API (AWS AppSync) has a trick up its sleeve: You can create a Lambda function to have complete control over how the authentication works. This Lambda function can then be set as the authentication mechanism on the API instead of a Cognito userpool.
export const data = defineData({
name: 'fullstack-with-clerk',
schema,
authorizationModes: {
defaultAuthorizationMode: 'lambda', // set the mode
lambdaAuthorizationMode: {
function: APIAuthorizer, // apply the lambda function
},
},
})
Understanding AWS AppSync Lambda Authorizers
Lambda authorizers in AWS AppSync work differently than those found in other API services on AWS. In my opinion, they're much simpler.
In short, as long as you return an object with an isAuthorized boolean, you're all set. How you form the true or false value for that boolean is up to you.
Any authorization tokens passed to our API will appear on the event.authorizationToken parameter. In our application, we'll use the JWT of the user from Clerk, verify it, and then decode it to get the users sub. If all of that works, then we know they are authorized:
import { Handler } from 'aws-lambda'
import jwt, { JwtPayload } from 'jsonwebtoken'
import * as crypto from 'crypto'
import { env } from '$amplify/env/clerk-api-authorizer'
const jwkToPem = (jwk: string) => {
const keyObject = crypto.createPublicKey({
key: jwk,
format: 'jwk',
})
const pem = keyObject.export({
type: 'spki',
format: 'pem',
})
return pem
}
//make sure lambda runtime supports `fetch` (v >= 20)
export const handler: Handler = async (event: {
authorizationToken: string
}) => {
const token = event.authorizationToken
const secret = env.CLERK_API_KEY
const validDomains = ['http://localhost:5173']
const res = await fetch('https://api.clerk.com/v1/jwks', {
headers: {
Authorization: `Bearer ${secret}`,
},
})
const data = await res.json()
const pem = jwkToPem(data.keys[0])
let decoded: JwtPayload | null = null
try {
decoded = jwt.verify(token, pem) as JwtPayload
} catch (e) {
console.log('the error', e)
return 'Invalid token'
}
if (!decoded || !validDomains.includes(decoded.azp))
return { isAuthorized: false }
return {
isAuthorized: decoded.sub ? true : false,
resolverContext: { owner: decoded.sub },
}
}
A couple of notes on the code above:
The
envobject from Amplify is Gen 2 specific. More details can be found here. If not using Gen 2 (AWS CDK), you'll have to get the Clerk secret from SSM or another mechanism.The endpoint
'https://api.clerk.com/v1/jwks'was figured out by following the Clerk docs for manually verifying the JWT. The rest is just getting the returned keys, generating a pem file, and verifying the token with the pem.In the return statement, I'm passing
resolverContext. Think of this as metadata that by API resolvers can then make use of. It will be available ascontext.identity.resolverContext.owner. If you just want authenticated users to access your API, then this is not needed, but this is important is you want to scope data to a particular user.
The repo is a fullstack example with
react-router-dom. If you want to learn how to create a fullstack app with Clerk andreact-router-dom, checkout the getting started page from Clerk.
API Endpoints with Clerk and AWS AppSync
If your goal is to have Clerk provide the authentication for an app where everyone signs in and shares data, then the rest is pretty straightforward:
In your Amplify Gen 2 schema, you can have Amplify create your resources as normal:
const schema = a.schema({
Milestone: a
.model({
title: a.string().required(),
description: a.string(),
})
.authorization((allow) => [allow.publicApiKey(), allow.custom('function')])
})
That will create the resolvers for you to be able to to create, read, update, and delete.
However, typically, you'll want to scope those operations so that only the logged in user can manipulate the data, without affecting everyone else. This is called owner-based authorization, and what I'll show.
🗒️ The following JS resolvers work both with Amplify Gen 2 and the AWS CDK
Creating an item with owner
Imagine we already have a datasource: a DynamoDB table setup. Also, recall that our Lambda function used for authorization is passing the owner on the resolverContext.
import { util } from '@aws-appsync/utils'
import * as ddb from '@aws-appsync/utils/dynamodb'
// This is the request to our database
export function request(ctx) {
const { owner } = ctx.identity.resolverContext
const id = util.autoId()
const now = util.time.nowISO8601()
const item = {
...ctx.args,
id,
owner,
createdAt: now,
updatedAt: now,
}
const key = { id }
return ddb.put({ key, item })
}
// This is the response from our database
export function response(ctx) {
return ctx.result
}
Because AWS AppSync has first-class support for DynamoDB, we can make use of the AppSync util package, as well as the DynamoDB helpers package.
We combine those two to create things like a random id, set the time using now.ISO8601, and put the item in the table with its owner field.
The result is simply the item as it was stored in DynamoDB.
In short, any signed in user can create.
Getting an item by owner
When it comes to getting an item from DynamoDB, we effectively say, "Any signed in use can get an item from the database, but for the database to respond back to the client with the information, the owner field on the item has to match the owner field from the Lambda authorizer:
import { util } from '@aws-appsync/utils'
import * as ddb from '@aws-appsync/utils/dynamodb'
export function request(ctx) {
// get a todo by its id (API protects this so only auth users can call it)
return ddb.get({ key: { id: ctx.args.id } })
}
export function response(ctx) {
//if the owner field isn't the same as the identity, the throw
const { owner: clerkUser } = ctx.identity.resolverContext
const { owner: ddbOwner } = ctx.result
if (ddbOwner !== clerkUser) {
util.unauthorized()
}
return ctx.result
}
So long as that is the case, then return the data.
Updating an item if owner
Updating is fun because now we get to use DynamoDB conditions to do a lot of the work for us:
import { util } from '@aws-appsync/utils'
import * as ddb from '@aws-appsync/utils/dynamodb'
export function request(ctx) {
const { id, title, description } = ctx.args
const { owner } = ctx.identity.resolverContext
const now = util.time.nowISO8601()
const updateObj = {
title: ddb.operations.replace(title),
description: ddb.operations.replace(description),
updatedAt: ddb.operations.replace(now),
}
// update it if owner.
return ddb.update({
key: { id },
update: updateObj,
condition: { owner: { eq: owner } },
})
}
export function response(ctx) {
return ctx.result
}
Think of a form in a web app, were it populates all of the data about the item in various input boxes. The user can then update them and click submit. The backend get all of the information and simply updates the item in the database. What I love about updating is it shows the replace utility as well as the time.nowISO8601 utility for updating the timestamp.
Deleting an item if owner
Deleting is similar to getting an item, except we get to rely on DynamoDB conditions to make sure it's only deleted is the owner fields match:
import * as ddb from '@aws-appsync/utils/dynamodb'
export function request(ctx) {
// delete a todo by its id if it's the owner
const { owner } = ctx.identity.resolverContext
return ddb.remove({
key: { id: ctx.args.id },
condition: { owner: { eq: owner } },
})
}
export function response(ctx) {
return ctx.result
}
Pagination (listing items if owner)
I saved this one for last because it's its own way of doing things. In a naïve implementation, we may be tempted to just return an array of items. In fact, if we were scanning the table, that's what we'd get back. But in a real-world scenario, we want to efficiently query the data in our table and return a placeholder (token) if there are more items than our limit is set for:
import * as ddb from '@aws-appsync/utils/dynamodb'
export function request(ctx) {
const { owner } = ctx.identity.resolverContext
return ddb.query({
query: { owner: { eq: owner } },
index: 'milestonesByOwner',
limit: ctx.args.limit || 25,
nextToken: ctx.args.nextToken,
})
}
export function response(ctx) {
const { items = [], nextToken } = ctx.result
return { items, nextToken }
}
There's nothing inherently hard about this example, but it takes consideration. limit and nextToken aside, the index is what matters most here.
By default, our database is set with a primaryKey of id. However, for listing content, we want only search through items by their owner field. In short, we want a globalSecondaryIndex.
If not using Amplify and just using vanilla CDK, this can be achieved fairly easily as shown in my CDK starter repo. And if using Amplify Gen 2, this can be achieved as shown in the amplify/data/resource.ts file.
Conclusion
That's all there is :) The repo has all of the methods used on the frontend so that you can practice making calls to the backend. If you enjoyed this tutorial and would like to see AWS integrated with other resources, let me know by dropping a comment!
Until next time, Happy Coding 🦦